Aktien-Ticker selbst bauen und hosten
Programmieren muss man üben. Ich baue mir einene eigenen Aktien-Ticker
Warum einen Aktien-Ticker selbst bauen?
Als ich damit begann, programmieren zu lernen, habe ich dies vor allem über Onlinekurse und Youtube Videos versucht. Brav habe ich den Code abgeschrieben und dann gehofft, das alles so funktioniert, wie versprochen. Das hat es in den meisten Fällen auch, nur habe ich dabei leider nie etwas gelernt. Also begann ich damit, mir kleine Herausforderungen zu stellen und diese dann mittels Doku und ‘good ol’ Google’ selbst zu lösen. Das hatte dann den gewünschten Effekt und langsam, sehr langsam aber sicher, lernte ich Dinge zu programmieren. Eine solche Herausforderung stelle ich mir heute wieder.
Ich möchte mir einen Aktien-Ticker bauen, den ich selbst hosten kann. Ja, ich könnte hierfür Onlineportale nutzen, nur lerne ich nichts dabei und ich habe perspektivisch mehr damit vor.
Meine Ziele sind:
- LXC Container in Proxmox erstellen, auf dem alles, was ich brauchen werde, läuft
- Grafana installieren, für die Visualisierung
- InfluxDB installieren, weil diese für Zeitreihen besonders gut geeignet ist
- yfinance API mittels Python ansprechen
Wenn ich das zum Laufen bekomme, habe ich eine gute Basis, um darauf aufzubauen.
Let’s go
Schritt 1: Container einrichten
Ich erstelle mir einen LXC-Container in Proxmox mit den folgenden Daten:
- 2 vCPU Kerne
- 2 GB Ram
- 10 GB HD Speicher
Schritt 2: System vorbereiten
Ich aktualisiere erst einmal den Container und installiere auch gleich Python mit.
1
2
sudo apt update && sudo apt upgrade -y
sudo apt install -y python3 python3-pip curl git
Schritt 3: Installation von InfluxDB
Für meinen Ticker reicht InfluxDB v2. Es gibt auch eine v3, aber ich möchte die Installation einfach halten und benötige die neuen Features nicht. Ich richte mich nach dieser Anleitung. Damit ich influxdb in den LXC-Container installieren kann, muss ich zunächst die Paketquellen hinzufügen. Danach kann ich es per apt installieren.
1
2
3
4
5
6
7
8
9
10
11
12
# Ubuntu and Debian
# Add the InfluxData key to verify downloads and add the repository
curl --silent --location -O \
https://repos.influxdata.com/influxdata-archive.key
echo "943666881a1b8d9b849b74caebf02d3465d6beb716510d86a39f6c8e8dac7515 influxdata-archive.key" \
| sha256sum --check - && cat influxdata-archive.key \
| gpg --dearmor \
| sudo tee /etc/apt/trusted.gpg.d/influxdata-archive.gpg > /dev/null \
&& echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive.gpg] https://repos.influxdata.com/debian stable main' \
| sudo tee /etc/apt/sources.list.d/influxdata.list
# Install influxdb
sudo apt-get update && sudo apt-get install influxdb2
Ist die Installation durch gelaufen, kann die Datenbank gestartet werden.
1
sudo service influxdb start
Dass auch alles geklappt hat, überprüfe ich mit
1
service influxdb status
Ich entdecke Active: active (running).
Perfekt, läuft!
Weiter geht es nun im Browser. Dazu rufe ich die Container-IP + den Port 8086 auf.
 Das Onboarding für die Datenbank erfolgt dann im Browser
Das Onboarding für die Datenbank erfolgt dann im Browser
Die hier einzugebenen können frei gewählt werden, wir brauchen diese später für das Python-Script:
- Initial Organization Name: trading
- Initial Bucket Name: aktien-data
Im zweiten Schritt des Onboardings wird ein API-Token, welches ich mir gleich notiere, denn das brauche ich für das Python-Script.
Schritt 3: Grafana installieren
Um die Datenbankeinträge später visualisieren zu können, installiere ich mir Grafana. Dazu muss ich die Paketquellen erst einmal hinzufügen, um es installieren zu können. Ich halte mich an die offizielle Anleitung:
Benötigte Pakte installieren:
1
sudo apt-get install -y apt-transport-https software-properties-common wget
GPG-Schlüssel installieren:
1
2
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
Das Stable-Repo hinzufügen:
1
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
1
sudo apt-get update
Und nun kann Grafana installiert werden:
1
sudo apt-get install grafana
Prima, ich starte Grafana mit dem folgenden Befehl und überprüfe auch gleich, ob es gestartet ist:
1
sudo /bin/systemctl enable grafana-server
1
service grafana-server start
1
service grafana-server status
Grafana läuft, also geht es auch hier wieder weiter im Browser unter der Container-IP + Port 3000.
 Im Browser erledige ich das Onboarding von Grafana
Im Browser erledige ich das Onboarding von Grafana
- Username: admin
- Passwort: admin
Das Passwort muss im nächsten Schritt geändert werden, was ich dann auch fix mache. Grafana läuft also nun auch, also geht es nun mit dem Python-Script weiter.
Schritt 3: Python vorbereiten
Um die Aktienkurse zu laden, verwende ich yfinance. Mit diesem Python-Paket ist es möglich, die benötigten Daten von Yahoo! Finance per API abzufragen. Selbstverständlich ist es möglich, auch andere APIs zu verwenden. Dafür muss dann nur das Python-Script entsprechend angepasst und die benötigten Pakete installiert werden. Für meine kleine Herausforderung reicht mir das, was die API zurück liefert.
Als erstes lege ich mir einen Ordner an, in welchem ich meinen Python-Code ablege:
1
mkdir /opt/aktien-ticker
In diesen Ordner wechsele ich nun:
1
cd /opt/aktien-ticker
Hier lege ich eine virtuelle Umgebung an:
1
python3 -m venv venv
Diese aktiviere ich:
1
source venv/bin/activate
Nun arbeite ich innerhalb der virtuellen Umgebung. Jetzt installiere ich yfinance für die Aktien-Daten und influxdb-client um die Datenbank ansprechen zu können:
1
pip install yfinance influxdb-client
Alles klar, ich bin soweit. Nun mache ich mich ans Coden.
Schritt 4: Python Code erstellen
Ich lege die leere Datei an:
1
touch /opt/ticker_dashboard/aktienticker.py
Und bearbeite sie mit nano:
1
nano /opt/ticker_dashboard/aktienticker.py
Den Code schreibe ich lokal in VS Code vor, und füge den dann einfach ein.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import yfinance as yf
import logging
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
from datetime import datetime
# Konfiguration
import yfinance as yf
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
# Logging-Konfiguration hinzufügen
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
TICKERS = ["AAPL", "MSFT", "TSLA"] # Unternehmen, deren Aktien ich laden will
INFLUX_URL = "http://localhost:8086" # Pfad zur InfluxDB
INFLUX_TOKEN = "MEIN_NOTIERTES_ API_TOKEN" # Das notierte API Token
ORG = "trading" # Aus dem Onboarding
BUCKET = "aktien-data" # Aus dem Onboarding
# InfluxDB verbinden
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=ORG)
write_api = client.write_api(write_options=SYNCHRONOUS)
for ticker in TICKERS:
data = yf.Ticker(ticker).history(period="1d", interval="5m").tail(1)
if not data.empty:
row = data.iloc[0]
time = data.index[-1].to_pydatetime()
point = (
Point("stock_price")
.tag("ticker", ticker)
.field("open", float(row["Open"]))
.field("high", float(row["High"]))
.field("low", float(row["Low"]))
.field("close", float(row["Close"]))
.field("volume", int(row["Volume"]))
.time(time)
)
write_api.write(bucket=BUCKET, org=ORG, record=point)
logging.info(f"{ticker} geschrieben: Open={row['Open']}, High={row['High']}, Low={row['Low']}, Close={row['Close']}, Volume={row['Volume']}")
print("Daten erfolgreich in InfluxDB geschrieben.")
Das Array von TICKERS enthält die Aktienkurse, die ich einmal testweise laden möchte. Dies sind Apple, Microsoft und Tesla. Dieses Array kann ich natürlich ändern und frei anpassen. Im Groben macht dieses Script folgende Dinge:
- Import von
yfinanceundinfluxdb-client - Import von
logging, damit ich den noch anzulegendencronjobloggen kann - Konfiguration des Datenbankzugriffes
- Daten von Yahoo! Finance laden und in die Datenbank schreiben
- Infomationen, die geschrieben wurden, werden gelogged
- Ein
printfbestätigt mir, dass die Daten erfolgreich geschrieben wurden
Wenn ich nun einmal fix in der Weboberfläche von InfluxDB nachschaue, sehe ich, dass die ersten Daten eingetrudelt sind.
Das Script automatisiere ich nun noch einmal schnell mit einem cronjob:
1
conjob -e
Im Menü entscheide ich mich für nano und füge diese Zeile ein. Der Cronjob aktiviert die virtuelle Umgebung und führt dann das Script aus und dies alle 15 Minuten.
1
*/15 * * * * source /opt/ticker_dashboard/venv/bin/activate && /opt/ticker_dashboard/venv/bin/python /opt/ticker_dashboard/aktienticker.py
Schritt 5: Grafana
Um die Daten aus der Datenbank zu visualiseren, muss Grafana entsprechend konfiguriert werden. Ich melde mich dafür auf der Weboberfläche von Grafana an. Die Erstellung eines Dashboards ist per JSON möglich. Ich lasse mir den Code von einer beliebigen AI erstellen und teile mit, dass ich InfluxDB nutze und die Folgenden Datenfelder (also die von mir gewählten Aktien) anzeigen lassen will. Außerdem teile ich im Prompt mit, welche Daten man per API bezogen hat (Bsp. ‘Open’, ‘High’ … ‘Volume’) Ich möchte ein Candlestick Diagram für den Kurs-Verlauf und ein Diagram für das Volumen. Für den Anfang reicht mir das.
Natürlich können die hier angezeigten Daten und Visualisierungen geändert werden. Wichtig ist nur, dass Datenfelder angesprochen werden, die es auch in der Datenbank gibt.
Dieser Code sieht bei mir dann so aus.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
{
"title": "Aktien Ticker Dashboard (Candlestick)",
"timezone": "browser",
"schemaVersion": 38,
"version": 3,
"refresh": "5m",
"panels": [
{
"title": "AAPL Candlestick",
"type": "candlestick",
"datasource": null,
"fieldConfig": {
"defaults": {
"custom": {}
},
"overrides": []
},
"targets": [
{
"query": "from(bucket: \"aktien-data\") |> range(start: -1d) |> filter(fn: (r) => r._measurement == \"stock_price\" and r.ticker == \"AAPL\" and (r._field == \"open\" or r._field == \"high\" or r._field == \"low\" or r._field == \"close\")) |> pivot(rowKey: [\"_time\"], columnKey: [\"_field\"], valueColumn: \"_value\")",
"refId": "A"
}
],
"gridPos": {
"x": 0,
"y": 0,
"w": 8,
"h": 8
},
"options": {
"ohlc": {
"open": "open",
"high": "high",
"low": "low",
"close": "close"
}
}
},
{
"title": "MSFT Candlestick",
"type": "candlestick",
"datasource": null,
"fieldConfig": {
"defaults": {
"custom": {}
},
"overrides": []
},
"targets": [
{
"query": "from(bucket: \"aktien-data\") |> range(start: -1d) |> filter(fn: (r) => r._measurement == \"stock_price\" and r.ticker == \"MSFT\" and (r._field == \"open\" or r._field == \"high\" or r._field == \"low\" or r._field == \"close\")) |> pivot(rowKey: [\"_time\"], columnKey: [\"_field\"], valueColumn: \"_value\")",
"refId": "B"
}
],
"gridPos": {
"x": 8,
"y": 0,
"w": 8,
"h": 8
},
"options": {
"ohlc": {
"open": "open",
"high": "high",
"low": "low",
"close": "close"
}
}
},
{
"title": "TSLA Candlestick",
"type": "candlestick",
"datasource": null,
"fieldConfig": {
"defaults": {
"custom": {}
},
"overrides": []
},
"targets": [
{
"query": "from(bucket: \"aktien-data\") |> range(start: -1d) |> filter(fn: (r) => r._measurement == \"stock_price\" and r.ticker == \"TSLA\" and (r._field == \"open\" or r._field == \"high\" or r._field == \"low\" or r._field == \"close\")) |> pivot(rowKey: [\"_time\"], columnKey: [\"_field\"], valueColumn: \"_value\")",
"refId": "C"
}
],
"gridPos": {
"x": 16,
"y": 0,
"w": 8,
"h": 8
},
"options": {
"ohlc": {
"open": "open",
"high": "high",
"low": "low",
"close": "close"
}
}
},
{
"title": "AAPL Volume",
"type": "timeseries",
"datasource": null,
"fieldConfig": {
"defaults": {
"custom": {}
},
"overrides": []
},
"targets": [
{
"query": "from(bucket: \"aktien-data\") |> range(start: -1d) |> filter(fn: (r) => r._measurement == \"stock_price\" and r.ticker == \"AAPL\" and r._field == \"volume\")",
"refId": "D"
}
],
"gridPos": {
"x": 0,
"y": 8,
"w": 8,
"h": 8
}
},
{
"title": "MSFT Volume",
"type": "timeseries",
"datasource": null,
"fieldConfig": {
"defaults": {
"custom": {}
},
"overrides": []
},
"targets": [
{
"query": "from(bucket: \"aktien-data\") |> range(start: -1d) |> filter(fn: (r) => r._measurement == \"stock_price\" and r.ticker == \"MSFT\" and r._field == \"volume\")",
"refId": "E"
}
],
"gridPos": {
"x": 8,
"y": 8,
"w": 8,
"h": 8
}
},
{
"title": "TSLA Volume",
"type": "timeseries",
"datasource": null,
"fieldConfig": {
"defaults": {
"custom": {}
},
"overrides": []
},
"targets": [
{
"query": "from(bucket: \"aktien-data\") |> range(start: -1d) |> filter(fn: (r) => r._measurement == \"stock_price\" and r.ticker == \"TSLA\" and r._field == \"volume\")",
"refId": "F"
}
],
"gridPos": {
"x": 16,
"y": 8,
"w": 8,
"h": 8
}
}
],
"time": {
"from": "now-1d",
"to": "now"
}
}
Ich melde mich auf der Weboberfläche von Grafana an, klicke rechts oben auf das “+” Symbol und wähle Import Dashboard. In das Textfeld Import via dashboard JSON model füge ich meinen Code ein und speichere die Änderung.
Die Daten werden nun aus der Datenbank geladen und visualisiert.
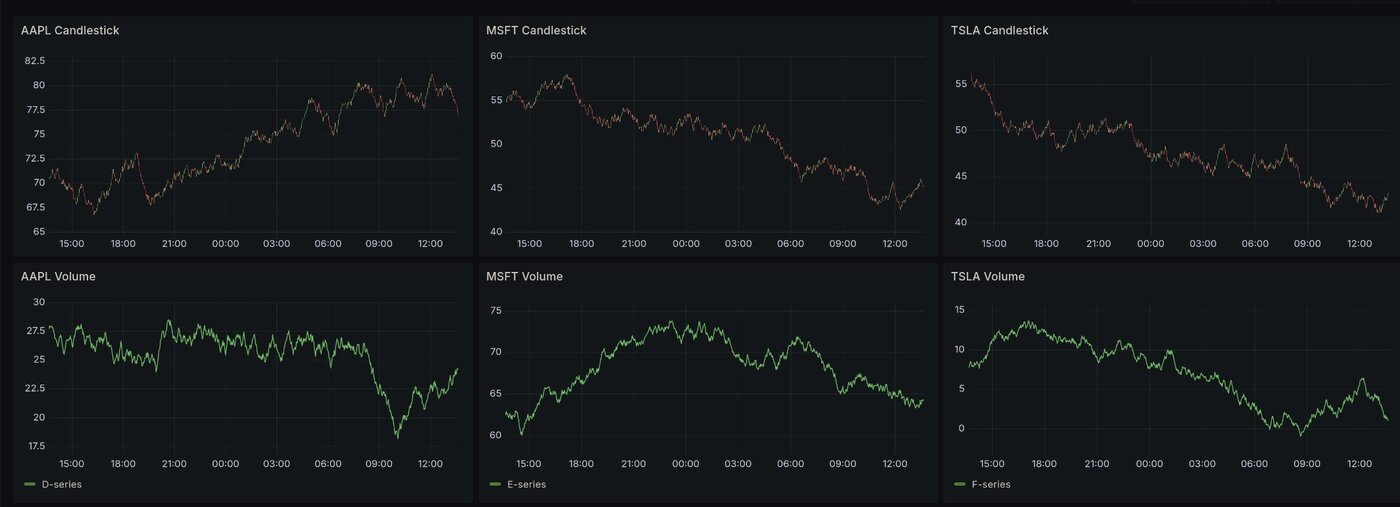 Die Charts der von mir gewählten Kurse wird nun angezeigt
Die Charts der von mir gewählten Kurse wird nun angezeigt
Fertig! Und nun?
Dieses kleine Projekt hat mir Spaß gemacht, ist aber aktuell nicht mehr, als eine Finderübung. Ich habe das erste Mal mit InfluxDB gearbeitet und konnte mich in Python und Linux austoben. Grafana ist für sehr viele Dinge sehr nützlich.
Allerdings ist das Dashboard noch nicht sehr hilfreich. Die Daten, die ich bekomme, kann ich so jederzeit und auch viel besser auf zahllosen Internetseiten einsehen. Aber, ich wollte ja auch erst einmal nur das Fundament legen.
Meine nächsten Ziele sind:
- Das Grafana Dashboard aufboren (Filter,verschiedene Dashboards für verschiedenen Werte, mehr Visualisierungen)
- Grafische Oberfläche bauen, um Aktien hinzuzufügen und zu entfernen (vermutlich mit Flask)
- Die Datenbank um Informationen zu den getrackten Unternehmen erweitern
Das klingt nach viel Arbeit. Aber nur so werde ich programmieren lernen.